This is a self-summary of key takeaways from LLMs Get Lost In Multi-Turn Conversation paper. Please contact me if you find any inaccuracies.
Take away
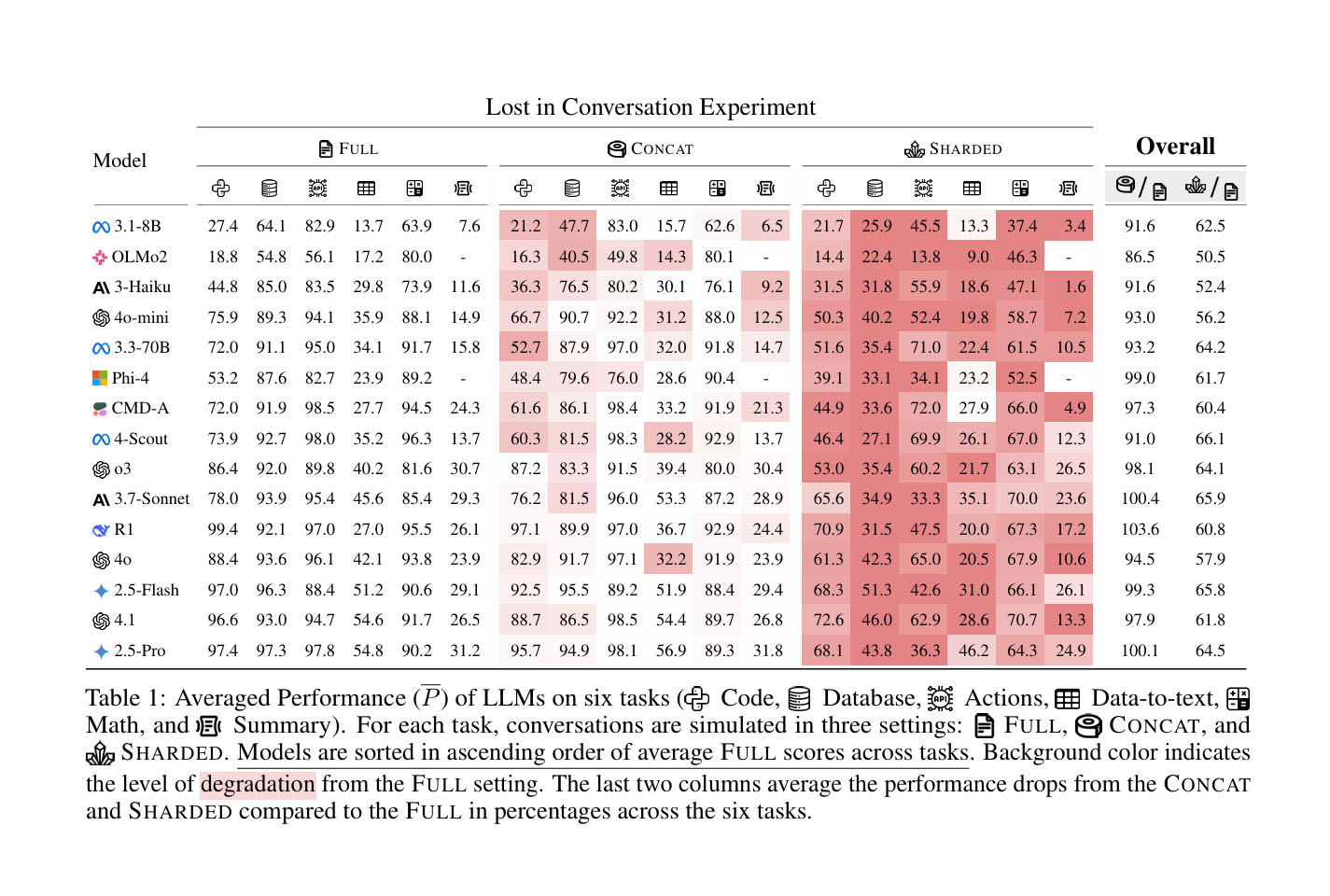
- Total 15 LLMs was tested, from smaller models like Llama3.1-8B-Instruct to top market leaders like GPT-4.1 or Gemini 2.5 Pro. All showed a significant performance drop (average 39%) in multi-turn conversations compared to single-turn. This indicates that even the most advanced LLMs struggle with extended conversations
At a high level, every model sees its performance degrade on every task when comparing FULL and SHARDED performance, with an average degradation of -39%. We name this phenomenon Lost in Conversation: models that achieve stellar (90%+) performance in the lab-like setting of fully-specified, single-turn conversation struggle on the exact same tasks in a more realistic setting when the conversation is underspecified and multi-turn.
From section 6.1. Average Performance Findings (Page 8)
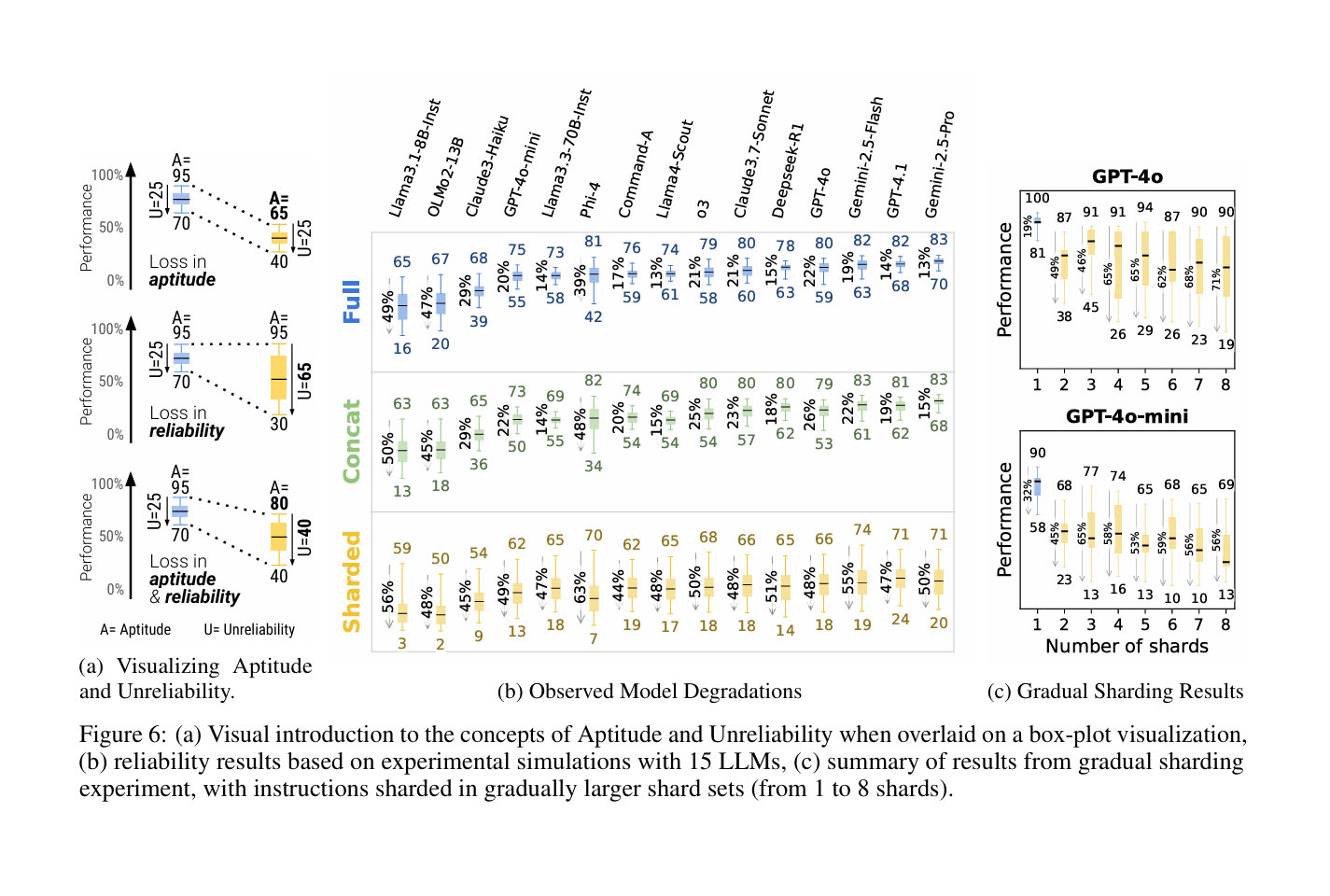
- More interestingly, though better models tend to have slightly higher multi-turn aptitude, all models tend to have similar levels of unreliability. In real-world tests with the same instruction and no specific configuration, results varied widely, with the worst runs showing an average performance drop of 50% compared to the best runs. This refines our definition of the lost in conversations phenomenon: when comparing single- and multi-turn settings, they found that the large performance degradations are due in large part to increased model unreliability, rather than a loss in aptitude
-
2-turn is already enough to poisoned context
-
Most LLMs tend to make risky early assumptions at the beginning, which is a key reason why multi-turn performs poorly. They stubbornly stick to these assumptions, making it extremely difficult to steer them back to accurate results through further conversation
In this work, we conduct a large-scale simulation of single- and multi-turn conversations with LLMs, and find that on a fixed set of tasks, LLM performance degrades significantly in multi-turn, underspecified settings. LLMs get lost in conversation, which materializes as a significant decrease in reliability as models struggle to maintain context across turns, make premature assumptions, and over-rely on their previous responses. Additional experiments reveal that known remediations that work for simpler settings (such as agent-like concatenation or decreasing temperature during generation) are ineffective in multi-turn settings, and we call on LLM builders to prioritize the reliability of models in multi-turn settings.
From section 8. Conclusion (Page 13)
- Models that provide longer responses (like reasoning models, such as DeepSeek-R1) tend to make more assumptions, which can lead to more confusion and derail the conversation, since their reasoning is included in the context. On average, reasoning models produce responses 33% longer than other models. The paper mentions that adding test-time (reasoning tokens) doesn't improve the effectiveness of multi-turn
Additional test-time compute (reasoning tokens) does not help models navigate multi-turn underspecification, as the two reasoning models included in the experiment (o3, Deepseek-R1) deteriorate in similar ways to non-reasoning models. This result confirms that additional test-time compute does not, on its own, allow models to strategize over multi-turn conversation. The analysis we conduct identifies a potential root cause: reasoning models tend to generate lengthier responses (on avg. 33% longer than non-reasoning LLMs). As we find in Appendix F, longer assistant responses tend to contain more assumptions, which can derail the conversation by confusing the model on what requirements were posed by the user vs. its own previous turn responses.
From section 6.1. Average Performance Findings (Page 9)
- Recapping or snowballing previous details for the LLM can reduce the model's stubbornness
..., we implemented two agent-style conversation simulation types: RECAP and SNOWBALL. Both preprocess user utterances before sending them to the LLM. In RECAP, a conversation proceeds in the same way as SHARDED, but a user turn is added at the end, which recapitulates all the previous user turns. SNOWBALL is a more gradual recapitulation: at each turn, the user simulator reveals a new shard, and repeats all previously revealed shards at that point. Both simulation types repeat the past user’s turn information to make it more prominent and give the LLM a chance to leverage the redundancy to improve its responses.
From section 7.1. Implications for System and Agent Builders (Page 10)
Reference
Original paper: LLMs Get Lost In Multi-Turn Conversation
Authors: Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, Jennifer Neville